Exploring Bioinformatics Databases: Your Guide to 6400+ Biological Repositories
Explore 6400+ biological databases like DDBJ and TrEMBL. Unlock the secrets of biological research. Dive in now and elevate your understanding!

AI Research Assistant
Analyze this article instantly
Biological databases are of significant importance in the field of bioinformatics, as they serve as structured repositories for a diverse array of biological data. Researchers utilize these databases to facilitate the storage, retrieval, and analysis of information about proteins, nucleotides, and other biomolecules. This enables researchers to make significant advancements in the fields of genomics, proteomics, and related areas of study. This article dives into the different types of biological databases, including their distinct characteristics.
There are several types of biological databases that researchers uses to store and access various types of biological data. These databases include sequence databases, which store DNA and protein sequences, and structure databases, which store information about the three-dimensional structures of proteins.
Biological databases are commonly categorized into three main types: primary, secondary, and composite databases.
Primary databases are a crucial resource for researchers.
Primary databases, also referred to as archival databases, consist of raw data that has been derived from experiments. Researchers typically use repositories as the primary source for data collection, where they directly submit their findings. Research data in primary databases are typically uncurated, meaning they are not altered or modified after they are submitted. Additionally, each entry in these databases is assigned a unique accession number for easy identification.
Some examples of primary databases include:
GenBank is a comprehensive database of nucleotide sequences maintained by the National Center for Biotechnology Information (NCBI).
The DNA Data Bank of Japan (DDBJ) is a nucleotide sequence database that collaborates with GenBank and EMBL.
The Protein Data Bank (PDB) database houses the three-dimensional structures of proteins and nucleic acids.
Secondary databases
Secondary databases are an important resource for researchers. They provide access to existing data collected by other researchers or organizations. These databases can include a wide range of information, such as survey data.
Secondary databases are created by researchers or organizations using data that has already been collected for other purposes.
Some examples of secondary databases include the National Health and Nutrition Examination Survey (NHANES), the World Health Organization (WHO)
UniProt is a valuable resource that offers comprehensive information on protein sequences and functions. It consists of two main sections: SwissProt, which is manually curated, and TrEMBL, which is automatically annotated.
InterPro is a database widely used by researchers to classify protein sequences into families and obtain valuable functional information.
Composite databases
Composite databases are a type of database that combines data from multiple sources into a single, unified view. These databases are designed to provide researchers with a comprehensive and integrated dataset that can be used for analysis.
Some examples of composite databases include
The Protein Data Bank (PDB), the National Center for Biotechnology Information (NCBI) databases, and the European Bioinformatics Institute (EBI) databases.
Swiss-Prot and TrEMBL are two databases that are combined to provide a comprehensive collection of protein sequences. Swiss-Prot contains curated protein sequences that researchers have carefully annotated, while TrEMBL consists of automatically annotated entries. Researchers can access a wide range of protein information by combining these two resources.
OWL (Ontology Web Language) is a framework that is used to represent complex data relationships.
Specialized biological databases
These are repositories of curated and organized data that focus on specific areas of biological research. These databases contain information related to various aspects of biology, such as genes, proteins, pathways,
Furthermore, specialised databases exist that cater to specific research areas or organisms in addition to the main categories.
Nucleotide databases, such as ENA (European Nucleotide Archive) and ArrayExpress, primarily specialize in functional genomics data.
Protein Sequence Databases: Protein Sequence Databases encompass databases such as PIR (Protein Information Resource) as well as specialized databases dedicated to protein families and domains.
Access the Biological Database at ResearchMatics
At researchmatics.com we have provided a comprehensive list of biological databases of more than 6400+ repositories. Which can be accessed here. The database is carefully curated and provides extensive information to facilitate the research.
The biological database is maintained and up to date, easy to access, and categorized in required fields so that you may access it easily.
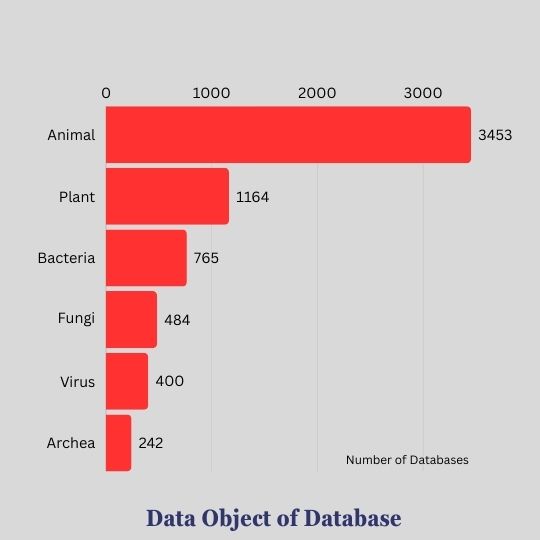
The Database contains data for various data objects like Animals, Plant Bacteria, etc.
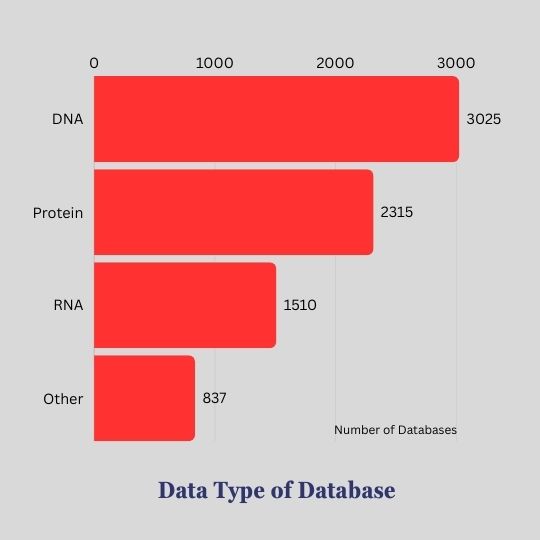
Data Types: DNA, RNA, Protein and Some other
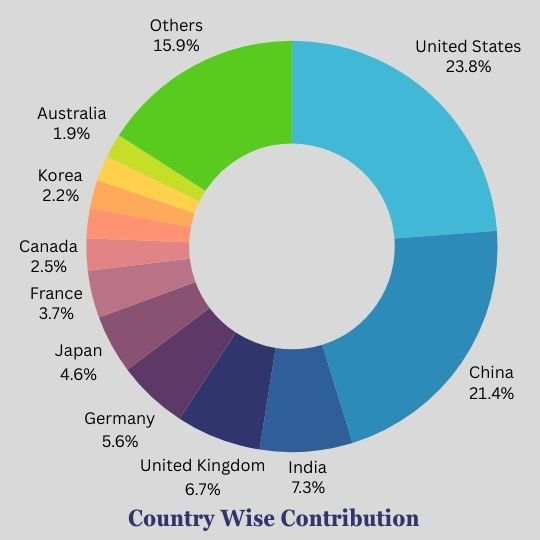
Country-wise distribution to Open Source data
The importance of biological databases
Biological databases play a crucial role in scientific research for a variety of reasons:
Knowledge Discovery: By organising extensive datasets, these databases enable researchers to uncover novel biological insights.
Data management is a crucial aspect of research, particularly in biology. It plays a vital role in eliminating redundancy and ensuring the integrity of biological data.
You may also access journal Impact factor report for 2024 here.
In conclusion
Biological databases are indispensable tools that support a wide range of biological research activities. From storing nucleotide and protein sequences to integrating data from multiple sources for complex analyses, these databases provide the foundation for modern biological discoveries. Understanding the different types of bioinformatics databases and their applications is essential for anyone involved in biological research or data analysis.
As the field of bioinformatics continues to grow, the importance of these databases will only increase, driving further advancements in our understanding of life at the molecular level. Whether you are exploring the DDBJ for nucleotide sequences or leveraging TrEMBL for protein data, these resources are invaluable for the scientific community.
By staying informed about the latest developments in bioinformatics databases, researchers can continue to push the boundaries of what is possible in biological research and medicine.




